

Reduction and Multiple Levels of Description
In which I talk about computers and pretend it's philosophy

I suspect that, underlying a lot of traditional philosophical conundrums, is a difficulty of wrapping one's head around accepting multiple levels of description being simultaneously true.
Free will is a great example of this. As I've argued elsewhere, I think the key to understanding free will is realizing there are multiple levels at which we can think about the causes of our actions. Seeing the deterministic laws of nature as precluding ourselves from having a causal impact is a category error.
I suspect the standard arguments about consciousness are caused by the same thing.
One thing that's helped form my conception of the importance of different levels of description is studying computers.
Computers are human-engineered, so we understand all the parts down to the levels of physics and chemistry. But we talk about them at a bunch of different levels: users think in terms of the graphical displays they interact with, programmers write the code behind software and applications, other programmers think about different code (compilers, operating systems, etc.) that undergird that software, computer hobbyists and designers think about the computer parts that run those systems, and computer engineers think about the design of the circuits on silicon chips that make up the computer parts.
Each of these levels is useful to talk about. Each is real.
But talking about this in such a vague abstract way leaves a lot to be desired. So now that I've given some hand-wavy explanation of why this is philosophically motivated, let's spend a bunch of time learning about computers.

Electric Circuits to Logic Gates
Understanding a computer is mostly about understanding how a processor works. Everything else is obviously important in various ways, but it's the processor that's Turing Complete, which is sort of the magic property that makes a computer a computer.
A computer's processor is built out of transistors. Transistors are electrical components that have three terminals: control, input, and output.

The easiest way to think about them is as a switch—transistors are literally switches completing specific circuits to allow electricity flow through them. When current is running to the "control" terminal of the transistor, the switch is turned on. Otherwise it's turned off. That's it, it's just a switch controlled by electric current.
Despite their simplicity, transistors are the basic building blocks of computers. This simple ability to control the flow of an electric current by using electric currents itself is what opens the door to modern computers.
You start by building up logic gates using transistors. Logic gates are a physical instantiation of certain logical operations—Boolean algebra, for the geeks.
Boolean algebra is all about taking two inputs that are on or off (1 or 0) and performing some function to decide whether the output is on or off. For example, AND is a function where if both inputs are on, the output is on, but if either input is not on, the output is off. It's called AND because, well, this signal AND that signal need to be on. This is opposed to OR, where either can be on and you get an on output.
If you know a bit about how electricity works and how transistors work, it's easy to figure out how an OR or AND gate works: for an AND, you set up the transistors in series, so both "switches" need to be "ON" to complete the circuit. For OR, you set them up in parallel, so if either one of the switches is "ON" it completes the circuit.
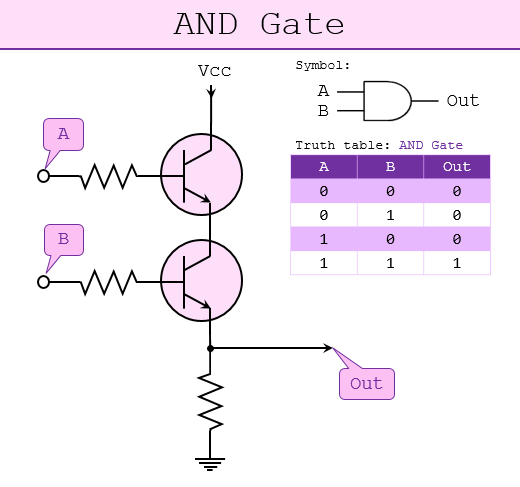
An AND gate might seem like barely a step up from a transistor. Now current passes through if two other wires have current instead of one. So what?
It turns out, combining a bunch of logic gates together, you can perform addition. Specifically, if you have an AND gate and an XOR gate, you can create a circuit that performs binary addition of two single-digit numbers (so you can add 1 + 1 and get 2). Stack enough of those together, and you can build adders that can sum larger numbers.
You can build multipliers and subtracters as well, and with these building blocks, you can put together an arithmetic logic unit, a central part of your computer's central processing unit.
Similarly, you could build up the other parts a computer requires—flip-flops (my favorite due to the name) to store values, multiplexers, and so on, and put them together to get the rest of your central processing unit.
Code on Code Action
That's the way-too-quick version of what it takes to make a computer. But how does this relate to what it means to actually write and run software?
Your computer has a Central Processing Unit (or multiple, since we're well into the age of multi-core processing, but let's ignore that). One part of the CPU, the control unit, is what receives an "instruction". In terms of our logic gates and transistors, an instruction is just a specific set of wires in the control unit receiving current.
When the computer's "clock" ticks (this is what the "hertz" of a CPU tells you, how quickly the clock ticks), that gives the processor the "go" signal, releasing the instruction. It's wired up in such a way that specific wires being active performs very specific actions for pulling data from memory, like reading data from a specific place in memory to place in one of the CPU's "registers" (the CPU's "working memory"), or taking two numbers from the registers and adding them together and placing them in another register. Or telling it to jump to another place in memory to read the next instruction.
The set of instructions the control unit can carry out is everything your computer can do. Luckily, modern computers are designed such that their set of instructions is Turing Complete, which means it can do any computation.
Instructions going into your CPU are literally ones and zeros saying which wires in the control unit should be active for the next clock cycle. Those instructions look like this (I'm using MIPS here as an example, for the nerds):
000000 00001 00010 00110 00000 100000
This is called machine code. It's as close as you can get to what is physically going on in your computer. The above code takes the contents of registers 1 and 2, adds them together, and places them into register 6.
It's not pleasant to write machine code as a human (I had to do it in one of my undergrad classes)—it's not very readable. Technically, you can write all code in it, but doing so would be a nightmare—especially figuring out where you had a mistake in your code.
Through the magic of code acting on code, we can create assemblers. These are computer programs that take a more human-readable version of a machine code instruction and translate them into the binary representation.
For example, the above can be written in assembly:
ADD $6,$1,$2
This is simply a human-readable way of writing the exact same phrase. There's a one-to-one correspondence between assembly and machine code.
But it became very obvious very early how cumbersome writing in assembly is. It might be readable for a human, but doing even basic things that are common in programming takes many lines.
For example, the above instruction assumes we already have data in registers 1 and 2, and that we want the result in register 6. Realistically, we need to first have an instruction load the relevant data into registers 1 and 2, and then take the result from register 6 and store it back in memory. This adds (at least) 3 more instructions, just for adding two numbers together.
A modern programming language would just be:
c = a + b;
The weakness of assembly is that it requires you to keep track of what's in each register at each step, and painstakingly put things into registers or take the results of an operation from a register and put it in memory at each step.
Along came compilers. Compilers take a higher-level language and translate them into assembly. There isn't a 1-to-1 mapping between a line of more abstract language and the compiled machine code, but there is a deterministic translation from one to the other.
It takes common operations (like arithmetic operations and branching logic, like loops) and abstracts away all of the register management nonsense.
This higher level of abstraction is essential for modern programming.
Not only do higher levels of abstraction make programming easier, but being abstracted away from the hardware means (some) programming languages allow programmers to completely ignore what hardware the code will be run on. An underlying compiler might handle translating from the higher-level code to the machine code, so even if the architecture of your CPU is different (meaning you have different machine code), the same high-level code can result in the same software (the same principle holds for interpreted languages, like Python, but I'm only mentioning compiled languages for simplicity here). This means the same high-level concept of a program can be instantiated by different underlying operations—something philosophers refer to as multiple-realizability.
Most websites these days have at least some JavaScript that runs on your computer when you visit the website. That code is written once, for every computer, regardless of their CPU. Different CPUs use different machine languages, but as long as there is a computer program capable of taking that higher level language and translating it down for your specific machine code, it doesn't matter that on a different computer, it would be translated into a different machine code.
Summing Up
Anyone writing a high-level language like Python or JavaScript isn't going to have any idea what the CPU's registers are going to be doing to execute any given line of code. It's just not important, and when run on computers with different architectures, the same code will result in differences in the specifics of what the CPU is doing.
"Software" is a nebulous intangible concept in some sense. It can be instantiated in different physical ways on different computers and it doesn't describe a physical thing with physical causal properties. But there's nothing weird or mysterious about talking about it causing things. We can trace the whole causal path up or down the different layers of abstraction, and each layer is useful in its own right.
Many things in life are like this. The things we most care about in life—love, happiness, belonging, purpose—are abstract and intangible. In some sense they have no causal power, because it's the people motivated by these things that cause these things to happen (and the people themselves are made of lower-level stuff that you could say really is the cause).
But reducing them to their lower-level cause doesn't mean the higher-level concept goes away. Instead, just like learning how a computer program is implemented in physical hardware deepens and enriches our understanding of software, picking apart and understanding high-level concepts can enrich and deepen our appreciation for the things that make life meaningful.
And that's how I justified writing a post that is really just regurgitating my computer architecture class from undergrad as if it is philosophy.
Please hit the ❤️ “Like” button below if you enjoyed this post, it helps others find this article.
If you’re a Substack writer and have been enjoying Cognitive Wonderland, consider adding it to your recommendations. I really appreciate the support.
There's an important difference between reductionism and eliminativism. Reductionism, in most philosophically rigorous senses of the term, sees higher-level phenomena or theories as *grounded* in lower-level phenomena or theories. When a sufficiently strong connection has been made, the lower-level phenomena actually provide *evidence* for the higher-level theories. When this is the case, it is indeed wrong to say that the lower-level theory is the only legitimate way of describing the higher-level phenomena. Both theories really are just offering different descriptions of the same thing.
Eliminativism, on the other hand, is a possible explanation for a *failure* of reduction. One reason a high-level theory might fail to reduce to a lower-level theory is that the higher-level theory is simply wrong. This is the reason, to give just one example, why phlogiston theory does not reduce to modern models of oxidation. The world just doesn't have a referent for something with the properties posited of phlogiston.
Re: computer languages, it's important to remember we started at a relatively low level of physical theory. The more abstract theories that comprise the various languages were developed within the known constraints of the physical system that ultimately has to implement them, and this ensures relatively smooth reducibility. When it comes to human thought and behavior, though, the story has been rather messier. We didn't start with a rich understanding of the physical implementation level; we started with a bunch of "middle world" folk concepts and discovered deeper dynamics and regularities only later. It's an open question, then, which of our folk or higher-level scientific concepts actually *can* be grounded in the implementation level--at least without radical changes in their posited properties.
Smooth reductions are rare in science. Most inter-level theory articulations are fudged in various ways such that the higher-level theory works well enough for enough purposes that we continue to use it even thought it breaks down in some places where the lower-level theory doesn't. We can model a fluid as a continuous medium using the Navier-Stokes equations for a lot of purposes, but if we want to know how it behaves inside a cell or in highly rarefied conditions, we have to start taking individual molecular effects into account (because fluids aren't *really* continuous media). There's a lot of this sort of thing in science, and that's fine; modeling everything at the implementation level would be way too computationally burdensome. But these concessions to practicality don't (imo) license us to say that these different-leveled theories are equivalent or even equally well-evidenced.
Excellent article. I came at this from the same direction, learning about the layers of abstraction in computer technology long before reading anything about consciousness and the brain. (My day job is in IT. Over my career I've programmed everything from machine code to web apps.)
If we came across computing technology in nature, we'd likely discuss the higher level concepts as "emergent" from the lower ones. Some of us might even despair of ever understanding how Windows or Mac OS could even conceivably emerge from all those transistors. Even though we actually understand everything about these human-made systems, those levels of abstraction are crucial for working with it.
Once we understand this, it seems clear that much of the mystery of the mind amounts to not having those intermediate layers yet. Of course, the nature of biology puts this into a completely different category of difficulty compared to engineered systems. But understanding it doesn't seem so inconceivable anymore.