



Signals All Around Us
Machines do statistical learning and so do you

One evening as a kid, I went out to dinner with my aunt and uncle. When our food came, my uncle immediately reached for the salt. My aunt joked he was being stupid, putting salt on his food before he had even tasted it.
I immediately understood: if you haven’t tasted the food, you can’t tell if it needs more salt. Adding salt before tasting is irrational.
There was a logical necessity to this. If you haven't tasted it, how could you know?
It wasn't until adulthood that I realized this reasoning was wrong. Despite being an accomplished statistical learner myself (as all humans are), I was falling back into the world of hard rules. I wasn't accounting for the information my uncle could draw on to make his decision about salting his food: all the other meals he's eaten in his life. He had a big statistical sample to draw on. He wasn't being irrational, he just knew, in these circumstances, he likely would enjoy his food more if salted.
This is the flip-side of my previous post, where I talked about how many signals are noisy. They might be noisy, but there are more signals than we often realize.
The Ubiquity of Signals: Image Enhancement Magic
I used to laugh about the absurdity of all the television shows where they use a computer to "enhance" an image (CSI being a big culprit), a concept satirized here:
This kind of "enhancing an image" seemed downright silly. If the information isn't in the original image, you can't just get more information out. If an image is pixelated, you can't just "enhance" it away—the pixels are showing you the limits of the information in the image file. It was logically impossible to "unpixelate" an image—so I thought.
Along come the AI image enhancers. Some of the early ones didn't work well, and there are dangers of bias. For example:

That said, the ones on the market now actually seem to work pretty well.

Why is it possible to enhance an image like this? How can you get out more information than was in the original image? What I had failed to consider is the added information doesn't need to be in the image itself. There is information all around us on what things in the real world look like. These seemingly magical AI enhancers are just bringing some of that information to these pixelated images, using training data to make estimates of which information is relevant to which images.
The models are trained on images of what faces look like. They see pixelated faces and their non-pixelated counterparts. From this, they learn people have individual teeth, not a solid glob of white stuff in the mouth, so it can take the pattern of pixelated shades of white in the above picture and infer where there are likely individual teeth. By combining the information in the pixelated image with the many unpixelated mouths and teeth it's seen, it can infer what that particular mouth might look like.
It might make mistakes, and that's where the danger with these things lies. They just are trying to infer from the images they've been trained on. If they've mostly been trained on one kind of face (e.g. white folks), it's going to do a poor job generalizing to other populations, and will often create misleading images.
We have to remember the enhancements aren't being generated strictly from information in the image provided, but being inferred based on the image provided and all the images the model was trained on. The enhancements often produce at least very plausible enhancements just by adding the information of how the world usually looks.
LLMs and the statistical information in language
It isn't just images that have rich statistical information. Large Language Models (LLMs) like GPT4 can produce surprisingly human-like language because they've been trained on lots of language data, and a surprising amount of information exists just in the statistical patterns in text.
The quick introduction for those that don't know: generative language models like the GPT models are trained to predict the next word based on all of the words they've seen so far in a context. This prediction of the next word allows them to generate text, since you can feed in the text so far and ask it what word it thinks comes next.
It turns out if you train them on enough data (and structure the neural network in the right way), they can come up with extremely sophisticated representations of language that allow them to generate not just grammatical language, but text that seems plausibly written by a human.
These models seem to have a deep representation of various concepts—and they struggle just as much as humans to produce viable definitions of many of those concepts.

These models have picked all of this up from just statistical regularities.
The best demonstration of what these models learn comes from before all the current hype about LLMs. Word embeddings are mathematical representations of words, learned from the statistics of language. All LLMs represent words this way. There are various methods for generating them, but the basic idea is to look at many, many examples of when different words are mentioned—the context of the surrounding words can tell you the relationship between this word and others. I'm handwaving here to avoid getting into a full tutorial on embedding models, but the point is with just the statistics of when words appear around each other, you can mathematically map these relationships out and represent them as a point in a multi-dimensional space—think of it as a point on a graph.
The cool thing is, once you've represented each word as a single point, you can look at the relationships between the points, and it's easy to show that these techniques—again, just looking at the statistics of where words appear in relationship to each other in text—capture important aspects of the meaning of the words. For example, the distance and direction between "man" and "woman" is similar to the distance and direction between "king" and "queen". Similarly for changes of verb tense, and the relationship between countries and their capitals.
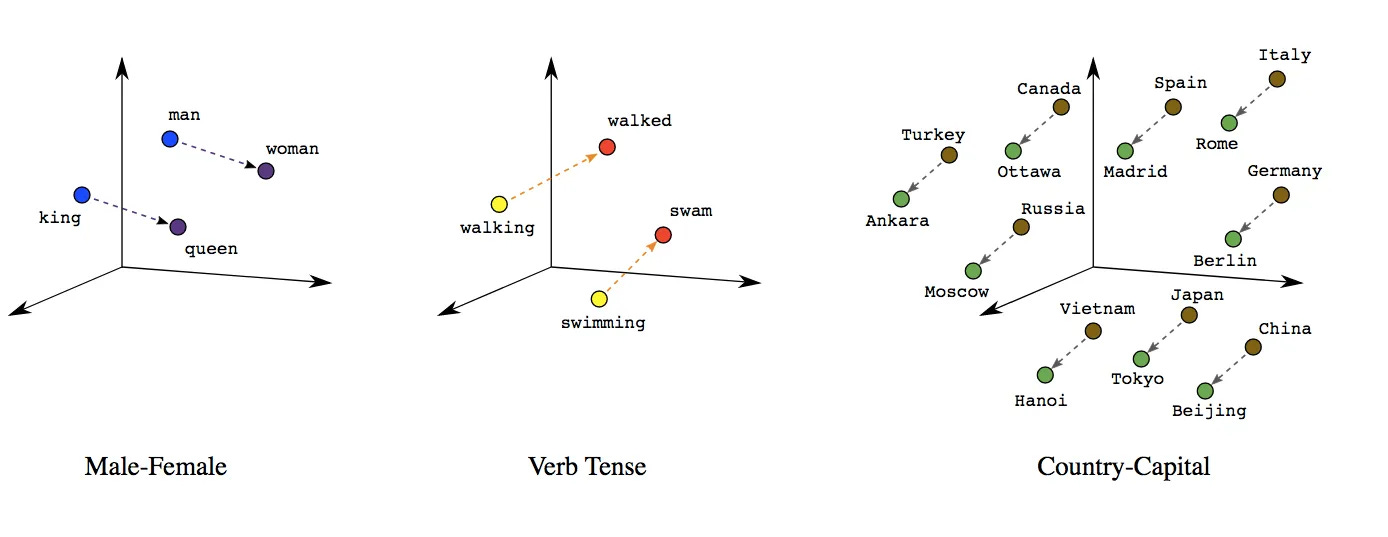
This is deep and interesting so bears emphasizing again: just using the statistical properties of when words are used tells you about the semantic relationship between all words.
These AI examples are meant to get across the point that there's more information all around us than we might naively realize hidden in the statistical properties of our environment. But it isn't just computers who can take advantage of it.
We are all statistical learners
Much is made of how poorly we reason in some circumstances, especially when it comes to numbers and statistics. Daniel Kahneman's best seller, Thinking Fast and Slow, catalogs the various ways we take mental shortcuts when thinking. Much less air time is given to just how amazing we are at picking up on statistical regularities.
Infants learn language through learning the statistical regularities in language. In any language, certain sounds follow the others with some regularity. We generally ignore these signals, but there is information there. And even babies can pick up on them.
For example, how do babies learn what a word is? I don't mean how they learn the meaning of a word, but actually being able to parse the sounds people are making into discrete words.
You might think that they just hear when one word ends and another starts, but it turns out we don't talk like that. When we're speaking, it's actually just a stream of sounds. Unlike with written word where we use spaces to differentiate words, spoken language has nothing to delineate where one word ends and another begins.

But there is statistical information. In every language, some sounds happen together in words more frequently.
In English, the syllable pre precedes a small set of syllables, including ty, tend, and cedes; in the stream of speech, the probability that pre is followed by ty is thus quite high (roughly 80% in speech to young infants). However, because the syllable ty occurs [at the end of words], it can be followed by any syllable that can begin an English word. Thus, the probability that ty is followed by ba, as in pretty baby, is extremely low (roughly 0.03% in speech to young infants)
Experiments have shown babies can pick up on these differences in how frequently sounds follow each other. By constructing a simple artificial "language" with made-up words, researchers can be sure the baby can't use other cues to differentiate the "words" and that the only cues to where words begin and end are in the statistics of which sounds follow which. After even brief exposure (2 minutes!), babies as young as 8 months old can differentiate the words in an artificial language. They've learned the language's statistics. Good babies.
This extends beyond sounds and words. Babies also pick up on these kinds of statistical patterns in experiments with visual rather than auditory patterns, suggesting this is a general learning mechanism used across sensory modalities.
According to William James, the world is a "blooming, buzzing confusion" for babies.
They need to build up structures to understand the world. The sensory input they receive, without structure, is meaningless. The light that enters our eyes and reaches our retinas doesn't have objects nicely picked out. We don't have obvious indicators of what light is coming to us from near objects versus far objects. Making sense of a visual scene is incredibly complex.
Our brains do copious processing, detecting edges so that distinct objects can be picked out and learning patterns that indicate what is near or far, and determine what is part of the same object or a different object.
Babies learn from the observation of their environment. While some of these abilities may be innate, the evidence seems to support that most of the understanding of our visual world is learned. Babies learn from the common structures of visual scenes and interacting with objects. The visual world is complex but also full of information that can be organized and learned.
The statistical regularities in our world allow babies to make sense of the world, from object recognition to language learning. The information is out there, but the signals are noisy—we all needed to pick up on the patterns and see it through the noise.
Bringing it all together
The world is noisy, but we're all equipped with statistical learning tools that help us navigate that noise. We are all natural statisticians, integrating complex information to inform important decisions (like whether to salt our food without sampling it first).
Modern AI has shown the power of learning from the statistical patterns all around us, the visual and linguistic. We've been using these same statistical patterns long before computers came along. We learn preferences, words, and objects through noisy patterns in our environments. I suspect much of our knowledge comes from this kind of learning—taking many, sometimes contradictory, examples and tracking the statistics well enough to pick up on the pattern.
In the next post I'll talk through how this relates to concept learning, and how this informs my thinking about philosophy.
If you enjoyed this post, consider sharing it. You can also help others find it by hitting the heart button to “Like” the post.
If you’re a Substack writer and have been enjoying Cognitive Wonderland, consider adding it to your recommendations. I really appreciate the support.
My dad also salted his food before he tasted it, and my mom‘s reaction was the same as your aunt’s. I will never forget the dinner at which my mom put a plate of food to which she'd already added salt in front of my dad and watched him salt it heavily. He then spit out the first bite and complained that it was too salty. My mom just laughed. He never again pre-salted her cooking.
I’d be interested to hear how this statistical mechanism contributes to how languages evolve. Whether a neologism needs to meet a predictable statistical threshold within a particular temporal window to be adopted by the speakers. What strength or intensity of statistical signal is needed over what period?