

Reality Filters 2: Bias in Man and Machine (Learning)
Understanding the data problems with human cognition

In the previous post, we saw how luck can be a big factor in what (or who) becomes successful/popular. To summarize, success requires high quality in some dimensions, but happenstance plays a large role in differentiating all the high quality candidates for success. A result of this is that successes tend to be high quality, and therefore we can come up with seemingly plausible explanations for that success even though happenstance played a large role.
Take, for example, Bill Gates (I'm consciously avoiding a certain other more controversial tech billionaire that would be more "of the times" to discuss. This is because I am too cowardly to get into internet fights about how luck played a role in his rise in fortunes).
Bill was a teenager during the age where computers were enormous industrial machines you needed to rent time on. After writing his first program using computer time paid for by his school, Bill was hooked and decided he needed to find more ways to get access to computers. He ended up finding and exploiting bugs in the operating systems of the computers of the Computer Center Corporation for free computer time. After being caught, he offered to help the company find bugs in exchange for more computer time. He ended up writing code to automate his school's payroll system before co-founding Traf-O-Data, producing software that read data from traffic counters to create reports for city governments. This was all while still in highschool—when he graduated, he went to Harvard (with near-perfect SAT scores), published original math research as an undergraduate before dropping out to work on Microsoft. The point is, the dude is smart, worked hard, and was really entrepreneurial.
If you asked why Bill Gates is so successful, many would point to these features. They wouldn't be wrong, but that's only part of the story. It leaves out the story of the many other smart, entrepreneurial people out there who work really hard and have their startups fail (or less dramatically, see their startups do just okay).
As I was reading Everything is Obvious (talked about in the previous post), it clicked with me that when we think of these big famous examples, it's easy to fall into traps reasoning about them because of sampling bias. We tend to think success is more probable than it is, more predictable than it is, and that we can learn more from it than we can, for all the same reasons it's hard to get an accurate survey of voting intentions: data sampling is hard. Many cognitive biases are better thought of as data sampling problems rather than just a list of arbitrary quirks in our cognitive systems.
Let's take a detour to learn about sampling bias before we come back to Bill Gates.
Sampling Biases

{kind=link}
I work as a data scientist. A huge part of the work is worrying about sampling biases in the data we use to train machine learning models. A sampling bias is when the method you use to choose your data leads to your data not being representative. If I wanted to conduct a poll on how Americans are voting in the next election, I could walk outside and ask random people on the street. This would have an obvious bias—the survey would reflect the political leanings of my particular town, and we know political leanings are quite different in rural Texas compared to urban Massachusetts (plus I would end up with people who are disproportionately pedestrians and willing to talk to some weirdo on the street). Instead, I would want to select individuals randomly from the entire country, ideally making my selections not based on any factors.
In reality, pollsters have to deal with issues like the bias of who is more likely to pick up their phone and answer questions. The simple act of being willing to answer your phone for an unknown number relates to age—I’m a millennial, and I immediately assume any call from a number I don’t recognize is a scam and won’t pick up. You'll end up with an age skew in your data, and we know age is a factor that is often related to voting preferences. The science of doing accurate polls is really a science of figuring out how to best avoid or correct for these types of sampling biases.
The differences in how easy it is to survey people can create a bias in your data. This is a great way to conceptualize a common cognitive bias: the availability heuristic.
The availability heuristic is a mental shortcut we all frequently use where we use how easily something comes to mind as a shortcut for predicting how common it is. This makes sense—if it's easy to remember or picture certain kinds of events, that's a good estimate that they happen often. But it leads to some interesting systematic biases in the real world. People tend to dramatically overrate the dangers of airline crashes, shark attacks, terrorism, and other emotionally salient events that get reported on the news.
There are two levels of sampling bias here. Networks "sampling" events to choose news stories to cover (and television shows and movies sampling what kinds of disasters to feature—I suspect kids think quicksand is much more common than it really is). They are going to be biased towards large, dramatic events they think people will be interested in.
The second level is the sampling of our memory. Not only are we exposed more to certain events, our memories also will find some memories easier to recall/sample because of their emotional salience. Big emotional memories "pick up the phone" and so are easy to think of, making them feel more common.
We are constantly exposed to the stories of famous, successful people. They appear in the news, they show up in social media feeds, and success stories are feel-good stories with clear emotional weight. This repetition and emotional component make success stories easy to remember and therefore make them easy for our memories to sample. We simplify thinking about success because we can easily think of individuals that "made it" who have some specific trait—talent, looks, family money, family connections—and assume those things assure success. But we're never exposed to the folks who have all of those traits and fail to succeed, so we underestimate the degree to which chance plays a role.
Machines Detecting Bots
Before going back to talking about Bill Gates, let's take a detour from our detour to talk about sampling bias to talk more about sampling bias.
Data scientists often build machine learning models to automate classifying data. Most commonly, they use supervised machine learning models, which learn patterns from having seen a bunch of data that already has the correct classification attached to it.
One problem companies use machine learning models for is to detect "bad actors" on their platform (full disclosure: this is part of my job). Bots on social media, fraudulent transactions with credit cards, phishers and spammers at email service providers, the list goes on. These companies have lots of data about each person or transaction, but figuring out what data indicates a bad actor is difficult. If we had a full "labeled" data set where all bad actors were classified as bad actors, it would be straightforward to create a machine learning model that could spot the right patterns and pick out the baddies. But to do that, you first need a method to label the baddies. You have a chicken-and-egg problem.
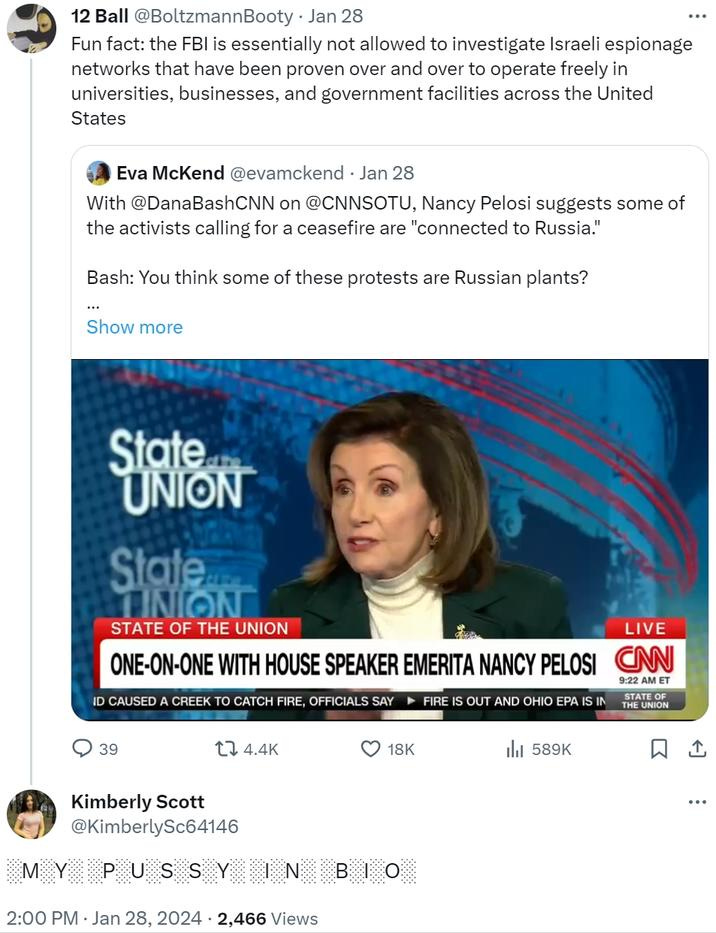
Let's say you're a certain owner of X/Twitter who I cowardly refrained from naming earlier in this post. You want to find bots on your platform. How do you bootstrap the process? You could set up some heuristics to catch really obvious ones, like keywords in posts that would indicate a bot—like the infamous "PUSSY IN BIO" that seemed to be every other reply on Twitter/X for a while. But then all of your examples of bots would be ones that post "PUSSY IN BIO". If you trained a model to recognize these bots, the model could do a perfect job on the data you've labeled just by looking for "PUSSY IN BIO" in replies—but you already have a heuristic for finding those accounts, so it wouldn't be a very useful model. The model won't generalize to other bots with different activity because your data is biased to such a specific type of bot.
Assuming it would be obvious to a human when an account is real or a bot, you could have someone sit down and go through a bunch of randomly sampled accounts on the platform, labeling each one in a tedious game of "bot or not". Since bots aren't common compared to good accounts (or wouldn't be, if you were doing a reasonable job in the first place), you would have to label a lot of data to even get a few examples of bot accounts. This is expensive to do accurately at scale, so you might end up with very few examples of bots.
Only having a few examples of bots is problematic since there are so many variables that could be related to being a bot. You could give a model all of that data—geolocation of the account gleaned from the IP address of the logins, time between posts, email domain used, username, login frequency, activity on the platform, content of posts, and so on. Because the model has so many variables to look at and so few data points, you risk overfitting: the model finding patterns that perfectly pick out the bots in the labeled data, but aren't real indicators. For example, if in your labeled data one bot had their username set to "Irene", and none of the good users had that name, a naïve model will declare anyone with the name "Irene" to be a bot with high confidence. When the model runs on real data, it'll decide everyone with the name "Irene" is a bot. Same thing if only one user was from an IP in Ecuador, or only posted on the weekend. With so many dimensions to pick up on, there is always something to distinguish a small set of data points. This is the curse of dimensionality.
So depending on how we've sampled the data, we might end up with "explanations" of how to tell a user is a bot that are just recapitulating a heuristic we used to select those users, or we could end up with explanations that are meaningless overfitting.
To tie up a loose end here before moving on—the way out of this chicken-and-egg problem of getting labeled data is pretty simple. 1) If possible, use reports of bad actors (complaints of fraud, reports of bots/spam from users, etc.). These might still have some bias in them based on what types of things people are most likely to report, but it's going to be better than the heuristic approach. And 2) use a combination of different labeling techniques. Gather some through a bunch of different heuristics, some from manually labeling data, some from user reports. It likely won't be perfect, but it will give you a greater variety of examples so your models generalize better and you can bootstrap from there.
Back to Success
Let's take a detour from our detours and get back to what this was supposed to be about to begin with: Bill Gates and successful people.
My claim is that we can use the concepts above about sampling bias and the curse of dimensionality to understand some errors in reasoning about success.
Entrepreneurs are systematically overoptimistic about their chances of success. I can't find direct data on it, but I'm willing to bet musicians, artists, and (gulp) writers are overoptimistic as well. It's cliche to talk about those who went to Hollywood naively thinking they could be the next movie star. Drug dealers and academics (that's right, same link for both) often deal with very poor working conditions early in their careers, justifying them with the chance they have to "make it big" as a ganglord or professor. Most of them (grad students or drug dealers) won't make it.
While there are other biases at play (like just general overconfidence effect in one's own abilities), part of the story is a sampling bias. Successes are overrepresented all around us. Famous people, artwork, media, and stories about them, are talked about more, are distributed more widely, and they stick around longer. People that don't see success just stop producing—their start up disappears, they don't produce more works of art, creating survivorship bias. You don't get to see every failed artist because their work never made it out of their basement. Unless you know them personally, you don't see how many writers toil away for years without publishing anything, but you can walk into a bookstore any time and see all of the published authors. There is a string of sampling biases reinforcing each other, making successful people overrepresented in what we see, obscuring the realistic view of what it's like trying to "make it".
It's easy to "sample" successes—opening up Spotify will overwhelmingly indirectly expose you to successful musicians, bookstores to published authors, shopping to successful entrepreneurs. We don't have a good way of sampling people who tried and didn't have the same breakaway success. Just like looking for bad actors, this gives us a bad sampling bias problem: we see the successes, who generally had to work hard and have a lot of talent. We don't see all those who worked hard, developed their skills, but ultimately didn't make it. Successful folks will tend to have traits that were necessary for success, but don't guarantee it, but in our everyday lives we'll only see the ones who had those traits and succeeded.
Given the small sample, we'll "overfit" to the examples of successful people, ending up with a biased picture that makes those successes seem easily predictable from their traits. We think we've really figured out what distinguishes the successful from the non-successful, and are overconfident in our ability to predict these kinds of success. In other words, these dynamics create hindsight bias.
The number of traits we can look at with successful people leads us to think we can learn more from them than we really can. It's easy to take any group of people and come up with some habits or personality traits they have in common. We can create post hoc explanations about what makes some individual or group of individuals successful and use them to write crappy articles about "the n habits of successful people" for any given number n. You can learn about what successful people eat for breakfast and also why they don't eat breakfast, or successful people wake up early but also successful people don't wake up early. The trick is just to use a small sample of our already small sample of successful people. With so many habits and so many successful people to choose from, you can choose pretty much any habit you want and find some examples and write an article about it. It's all just noise overfitting to some specific variable chosen out of thousands and applied to a handful of data points.
There's a very limited amount for us to learn from successful people. Bill Gates probably wouldn't have founded a successful software company if he wasn't smart and hardworking. But being smart and hardworking isn't enough to predict success. When we think of successful people, we look at just a few examples, chosen in a biased way from a sea of similar individuals that didn't make it. But because of all the sampling biases in what we're exposed to, we'll erroneously think success is more achievable and predictable than it is—and that we can explain and learn from the examples we see.
These general dynamics, that we have little to learn from particular examples because of all of the biases in the processes that generate the data, aren't just restricted to thinking about success. It's all around us pretty much every day. Understanding the processes that shape what we're exposed to can help us put the right epistemic weight on them. We'll explore that further in the next post.
Loving your use of metacognition inside your “detours”. let's take a detour from our detour to talk about sampling bias to talk more about sampling bias.
I’d argue that positioning is an aspect of “luck “ that gets almost no attention. Bill Gates is smart and capable but his cumulative positioning made it more probable for him to succeed. It put him where he could get opportunities and build on that.
Nice!